Modeling FAQs
Match Score
These FAQs offer a technical overview of our matching system. They describe how our match scores and match reports are calculated, how users can interpret results, and how we ensure that the results are accurate and free of bias.
-
What does the Match Score measure?
The AdeptID Match Score assesses the fit between a candidate and a job based on the candidate’s prior work history, skills, seniority, education, and more. AdeptID returns a match score that assesses the quality of the fit and a match report that explains the match score. The match report includes skills gaps and overlaps and a narrative summary of the match.
The Match Score is designed to mimic a recruiter's assessment process in an unbiased, data-informed, and efficient manner. It allows recruiters or candidates to identify whether a candidate or job is a good fit at a glance, reducing time spent manually searching and reviewing while improving outcome quality.
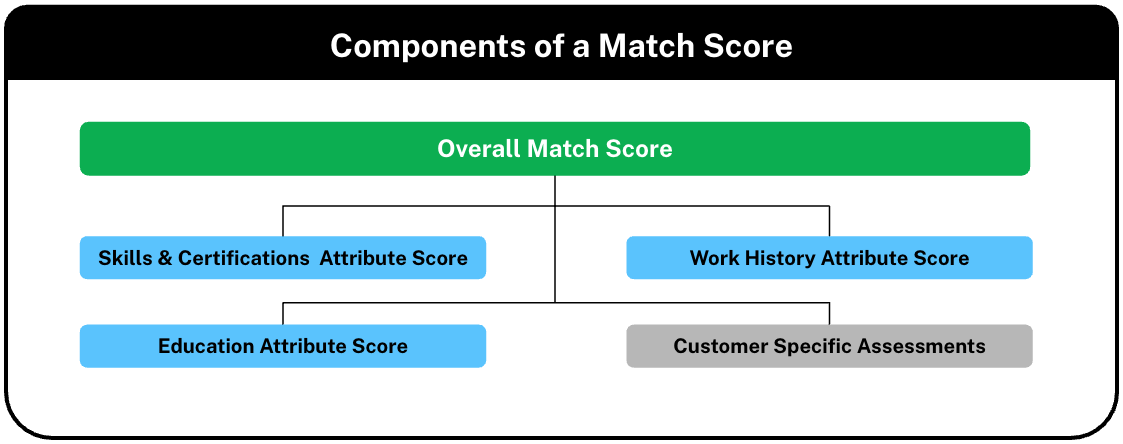
Each relevant dimension - work history, skills and certifications, seniority, education, etc. is modeled independently using responsible and transparent machine learning techniques before being combined into a single Match Score.
-
How should users interpret the Match Score?
AdeptID puts candidates into four categories based on their Match Score: ‘Very High’, ‘High’, ‘Medium’, and ‘Low’. The descriptions of each category are as follows:
- Very High (>90): Outstanding matches that likely warrant action from a recruiter (an invitation to apply for a role, interview, etc) or candidate (applying for the role, clicking into the job description to learn more, etc.).
- High (80-90): Good matches that may warrant action, with small and addressable gaps.
- Medium (70-80): Decent matches that can potentially warrant action by a recruiter or candidate when Very High or High matches do not exist or are in short supply. These matches have gaps/shortcomings, but also strengths.
- Low (<70): Poor matches with many gaps/shortcomings that do not warrant action by a recruiter or candidate.
-
How is the Match Score calculated?
AdeptID independently assesses candidates across relevant dimensions, including work history, skills, education, and seniority. For each dimension, we answer the question, "To what degree is this candidate a good fit for the job?" In some cases, external assessments provided by our partners are also factored into the match score.
However, a specific dimension might be more or less important depending on the job in question. When we combine the assessments for each dimension into a single Match Score, we weigh each to align with the importance demonstrated in real-world data.
The final Match Score is an "ensemble" of the multiple, independent assessments. In addition to the Match Score, AdeptID shares an “Attribute Score” for each dimension in order to increase explainability for users.
-
What data is used to train the Match Score models?
AdeptID’s Match Score models are trained on over two billion data points from industry-leading open and proprietary labor market data sources. For example, we process 60M resumes and online social profiles to assess the relevance of work history and seniority. From those resumes and profiles, we analyze 700M education and work experiences to model common job changes and career progressions. To assess the relevance of a candidate or job seeker’s skill set, we analyze 500M specific skills requested across 36M recent job postings.
The ensembling of the models considers the importance of each dimension for the role, with importance informed by millions of real job applications and interview/hiring decisions from partner Applicant Tracking System (ATS') and other tools.
-
What types of AI are used in the models?
We use a set of AI techniques and disciplines to understand candidate profiles and job descriptions, assess the fit between a candidate and a job, and explain the rationale behind our match. These include:
- Natural Language Processing: People represent themselves in writing - via resumes, cover letters, etc. Natural Language Processing helps translate human language into categories that our systems understand.
- Deep Learning: We have millions of examples of career paths, job applications, and other data sources about how employers hire and how candidates progress through jobs. Deep Learning helps us make sense of it.
- Information Retrieval: Users expect results fast. Information retrieval allows us to find the best candidates and jobs in milliseconds.
- Generative AI: We use generative AI to share results with users using easy-to-understand, natural language.
- Responsible AI: Throughout all of our work, we prioritize Transparent, Fair, and Accountable recommendations and assessments. We follow Responsible AI practices to do so.
Model Accuracy and Feedback
-
How do you measure the accuracy of your models?
The AdeptID Match Score is constantly improving. As we source more data, improve the design of our existing models, and add new models to represent new dimensions, we continuously measure our performance in terms of the questions that our users might ask. The below table details the statistical methods we use to evaluate our models as part of these continuous improvement efforts.
Considering the set of candidates recommended to a recruiter…_
| Questions a Recruiter Might Ask | Statistical Methods We Use to Answer the Question |
|---|---|
| How well does the Match Score predict the strength of the candidate? | Brier Score: The accuracy of our Match Score as a standalone predictor of whether or not an individual will receive a request to interview. |
| Are strong candidates always ranked higher than others? | Kendall Rank Correlation Coefficient: The relationship between the Match Score and the ordinal label; the closer to 1 the better. |
| How quickly can I find a strong candidate in the rankings? | Reciprocal Rank: Reciprocal rank measures 1 / (position of the first relevant candidate). The closer the reciprocal rank is to 1, the better. |
| How close to perfect are the recommendations? | Hit Proportion: The proportion of relevant candidates in the first R positions (where R is the total number of relevant candidates in an applicant pool). |
| Are any strong candidates missing from the recommended set? | Recall @ K: The proportion of relevant candidates that appear in the top K positions of an applicant pool. |
| Are all of the recommended candidates strong candidates? | Precision @ K: The proportion of candidates in the top K positions of an applicant pool that are relevant. |
-
How do you collect feedback, and what do you do with it?
AdeptID’s models are designed to recommend the best candidates for a job, and vice versa, based on what someone who is an expert in the field would expect to see. For this reason, real human feedback is essential to our processes and continuous model improvement. We systematically collect and use feedback in the following ways:- Programmatic Outcomes Collection: Our customer and partner systems share the results of our recommendations (e.g., Which candidates were interviewed for a job? Which jobs did a job seeker apply for?). We use this employment outcomes data to update our models and better reflect human preferences and decisions.
- End-User Provided Feedback: End users share feedback on individual match assessments via one of our feedback APIs. We conduct qualitative and quantitative reviews of this feedback on a regular basis and use it to identify and address gaps in our models.
Skills
-
How are candidates’ skills assessed?
A resume is an incomplete articulation of a candidate’s skills, making skill inference an essential step in providing an accurate assessment of a candidate’s fit for a job. For that reason, we build a skills profile for each candidate that combines the skills they explicitly list on their resume and the skills we infer they have (or could quickly learn) based on patterns learned from the hundreds of millions of analyzed resumes and job postings.
We take a layered approach to building a candidate’s skill profile:
- Skills Inferred from Titles: First, we look at a candidate's job titles and infer the skills they have likely developed by working in those roles. For example, our models assume that there is a very high likelihood that a Graphic Designer is skilled at Adobe Photoshop, and a moderate likelihood that they have more niche design skills such as logo design or data visualization.
- Skills Listed on Resumes: Next, we add the skills specifically listed on the job seeker’s resume. We consider skills called out in the skills section of the resume and those embedded in the descriptions of work and education experiences. We extract 29 skills from the typical resume.
- Skills Inferred from Other Skills: Finally, we infer additional skills based on the skills listed on a resume. For example, if a candidate indicates that they know HubSpot and Salesforce, we infer that they also have CRM and digital marketing skills.
In addition to identifying which skills a candidate possesses, we infer a degree of competence based on their time spent in jobs utilizing a skill and the level of competence with similar skills.
-
How are skill gaps and skill overlaps for a job determined?
For each match, we provide a match report which includes a list of skill overlaps and gaps. Skill overlaps are important skills that the candidate possesses and skill gaps are relevant skills for the job that the candidate may lack. To calculate these gaps and overlaps, we determine which skills are most important to the job, based on skills specified in the job description and skills we infer as important from analysis of similar jobs. We assess candidate proficiency across these important skills and compare the two values, reporting on the skills with the largest gaps and overlaps.
Generative AI & Narratives
-
How are Match Narratives generated?
AdeptID provides the option to generate a Match Narrative - a natural language summary to help users interpret an assessment - alongside each Match Score.
The Match Narrative is generated with the help of a Large Language Model (LLM) like ChatGPT, and communicates the primary drivers of a Match Score. These may include fit based on skills, work history, education, etc., as well as examples of important skills that a candidate does (not) have, (lack of) a required certification, a (non) relevant degree program, etc.
-
How do you ensure the LLMs do not ‘hallucinate’ results?
Common challenges with using modern LLMs include hallucination and bias. AdeptID prioritizes transparent, fair, and accountable AI; for that reason, we take significant steps to prevent hallucination and bias impacting Match Narratives. We do not use the LLM to derive any assessment of fit between candidate and job. Instead, we provide the LLM with quantitative assessments from the audited AdeptID models and only use the LLM to convert the model outputs into a natural language format.
Bias Mitigation and Compliance
-
How do you avoid bias in assessments and recommendations?
- Restricting Input data: Our models never see explicit demographic information or personally identifiable information. Name, ethnicity, etc., are not input to models during training or inference.
- Continuous Auditing: Our model development team and third-party auditors conduct regular audits on each new model version to confirm that assessments and recommendations are not biased based on demographics. While demographic information is never explicitly input to models, this testing ensures that inputs like job titles, which can be gendered, do not result in an aggregate bias.
- Explainability: All assessments and recommendations are accompanied by clear explanations, providing users with a report on the factors and considerations influencing each.
- Balanced Training Data: By embedding AdeptID solutions into HR systems (e.g., ATS) used by tens of millions of recruiters and job seekers across all types of roles, our systems and models gain a lens into the application outcomes of the vast majority of job types. This “full picture” of the actual labor market enables us to train balanced models that are not biased toward any specific type of role, industry, or career path.
-
How do you test that the Match Score is fair and unbiased?
We perform ongoing audits of our models to ensure compliance with relevant regulations related to disparate impact. For our latest audit results, visit https://trust.adept-id.com/.
Updated 11 months ago